
Zpracování a transformaci dat v rámci ETL procesů realizujeme v celé řadě nástrojů – například Google BigQuery, Keboola či Data Studio. Pro přehlednost, snadnou kontrolu celého datového toku a snadnější orientaci při úpravách či správě je pak pro nás důležitá vizualizace celého ETL procesu, a proto jsme začali vyvíjet Data pipeline vizualizaci v AppScript prostředí. Jedná se o přehledné schéma všech fází našeho ETL procesu a zároveň slouží i jako rozcestník na odkazy na dokumentaci či další nastavení. Vizualizace umožňuje také pro propojení lidí z více oblastí, kterých se ETL proces přímo nedotýká. Ten kdo zpracovává vizualizaci vidí, jakou cestou vznikla jeho zdrojová tabulka, datař má zase přehled nad tím, co se kde a kdy děje.
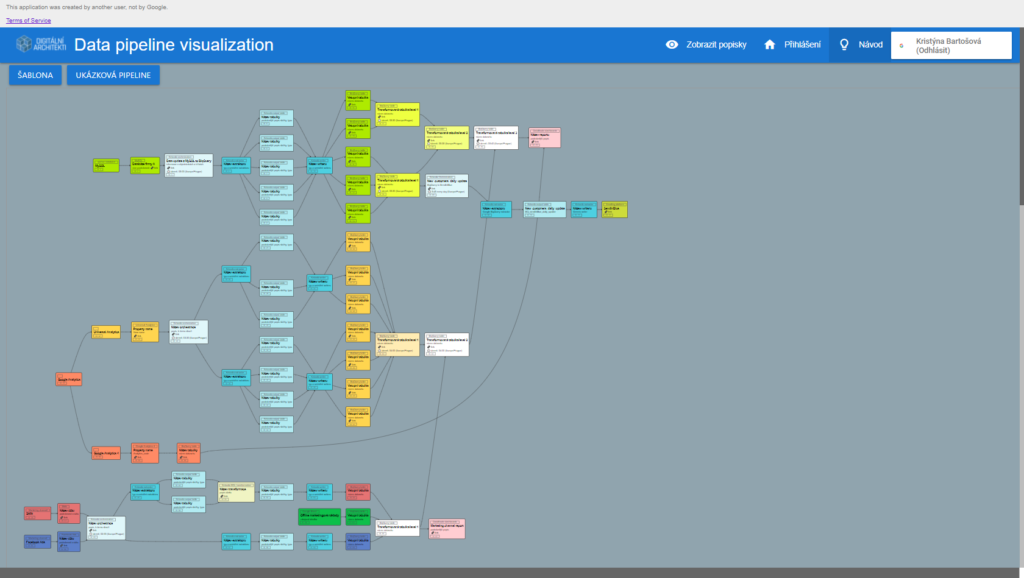
Hlavní výhody vizualizace ETL procesu
Vizualizace se sestává z buněk a propojovacích šipek, které definují jejich vzájemné vztahy. Každá buňka poskytuje dostatečný prostor pro vyplnění všech podstatných informací.
1. Variabilita
V každé buňce je prostor pro vyplnění základních informací o dané úrovni procesu. Máme zde prostor pro pojmenování konkrétního kroku ETL (výchozí databáze/Keboola extractor/BigQuery table/Data Studio report).
2. Přehlednost
Druhá řádka buňky se vztahuje k pojmenování daného kroku – název zdrojového účtu, název tabulky, pojmenování orchestrace. Třetí řádek je určen pro podrobnější popis dané buňky (například název datasetu), který může být rozšířen odkazem na dokumentaci tabulky či operace v řádku čtvrtém.
3. Lepší plánování
Navazující pátý řádek je vyhrazen pro informace o plánovaných operacích – kdy a jak často se nám v daném ETL spouštějí orchestrace či scheduled queries. Na další řádek je možno přidat další poznámky. Tento prostor ovšem využíváme málokdy, protože to hlavní je již uvedeno výše. Úplně v poslední řádce buňky se nacházejí buňky, které umožňují snazší orientaci ve vizualizaci.
4. Barevné značení
Barevné značení upravujeme na míru klientovi, aby měl nad procesy přehled. V našem případě ovšem barvy standardně definují jednotlivé datové toky ze stejného zdroje, popř. fáze na dataflow (např. Keboola, BigQuery, marketingové kanály).
Stejnou barevnost můžete držet pro danou dataflow až do momentu, kdy dojde ke spojení s jiným datovým zdroje (GA a marketing). V ten moment přecházíme na neutrální barvu, protože už definuje tabulku/úroveň, která vychází z více zdrojů.
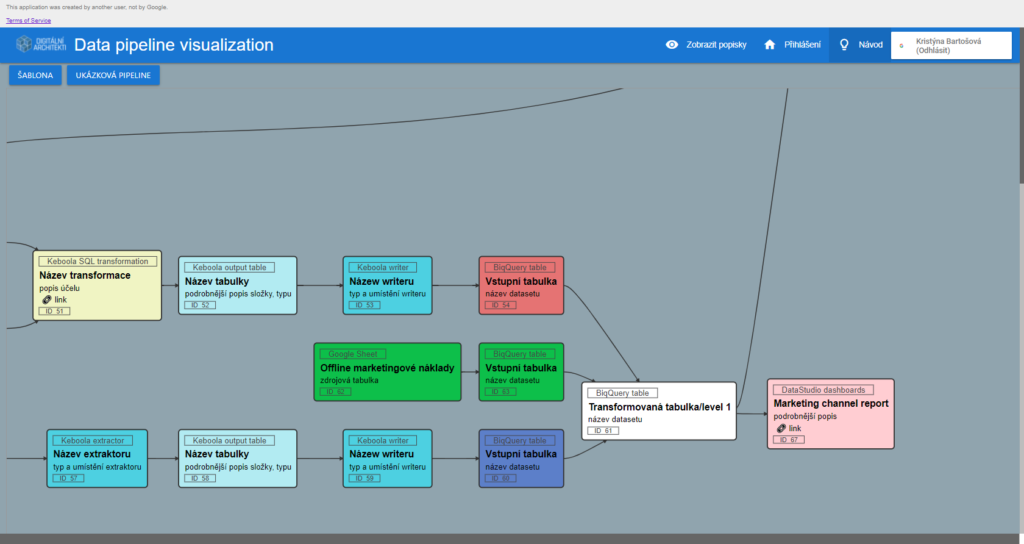
Navigace ve vizualizaci
Šipky
Jasné značení je pro nás zásadní – proto šipky na první pohled udávají vztahy uvnitř dataflow. Jsou výhodné hlavně při spojování více datových zdrojů, kdy snadno získáte přehled o všech zainteresovaných zdrojích.
Rozcestník
Vizualizace funguje i jako šikovný rozcestník, protože může obsahovat prokliky na všechny dostupné dokumentace, nastavení, zdrojové účty či finální výstupy ETL. Díky rozcestníku je usnadněna kontrola optimalizace procesu a jsme schopni se vyvarovat duplicitně nastaveným procesům.
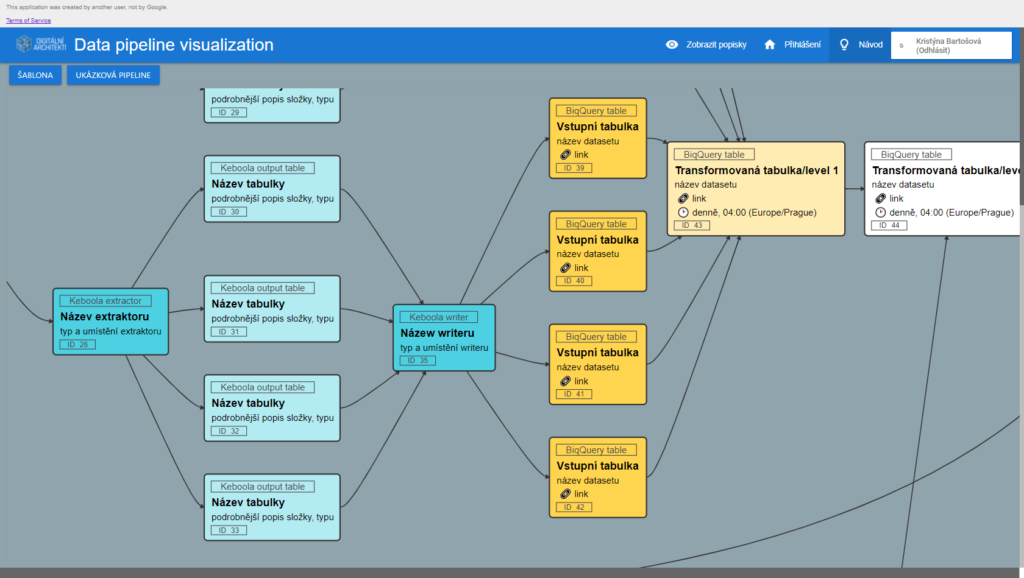
Důležitost vizualizace ETL procesů
Výhod je nespočet – o těch jsme napsali dost. 🙂 Kromě toho se jedná o praktický přehled pro všechny, kteří nejsou zainteresovaní – usnadnění pohledu zvenku na datové procesy.Každé řešení má samozřejmě i své určité limity. V případě AppScript je limitem počet buněk a tvorba šipek, pro někoho horší přehlednost a v některých případech překrývání buněk i samotných procesů). S tím ovšem dokážeme žít a pracujeme na vyřešení i těchto vad na kráse.

